Summer School: “People in the Digital Age” (Digital Prosopography)¶
Prepare¶
Jupyter notebook:
either install locally:
Install Python, pip and optionally virtualenv
run
pip install jupyterand start the notebook server with
jupyter notebook
or use colab:
Fork this repo: https://github.com/acdh-oeaw/summerschool2020-notebooks
and link your GitHub account to Colab
choose GitHub and the repo you just forked
open /session_3-2_NLP/Session 3-2 NLP (Wednesday 8-7-2020, 10 am).ipynb
Clone the GitLab¶
[1]:
import os
from getpass import getpass
import urllib
user = input('User name: ')
password = getpass('Password: ')
password = urllib.parse.quote(password)
cmd_string = 'git clone https://{0}:{1}@gitlab.com/acdh-oeaw/summerschool2020.git'.format(user, password)
os.system(cmd_string)
cmd_string, password = "", ""
User name: YourName
Password: ········
Importing Packages¶
[1]:
import os
import sys
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (20.0, 15.0)
import gensim
from gensim import corpora
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
from gensim.models import KeyedVectors
import networkx as nx
from sklearn.manifold import TSNE
from sklearn.cluster import AffinityPropagation, DBSCAN, AgglomerativeClustering, MiniBatchKMeans
from sklearn.decomposition import PCA
from ipywidgets import IntProgress
from IPython.display import display
from bs4 import BeautifulSoup as bs
from xml.etree import ElementTree as ET
some tools/libraries¶
Natural Language Processing (NLP) for Digital Humanities¶
Word embeddings
Word embeddings is one of the many ways to representing textual documents. It is capable of capturing the context in which words appear, given a corpus.¶
What are word embeddings exactly? Loosely speaking, they are vector representations of a particular word.¶
First, let’s see the most traditional way to represent word as vectors: a technique called “Bag of Words”:¶
Let’s suppose we have three documents:¶
Document 1 - “I am feeling very happy today”
Document 2 - “I am not well today”
Document 3 - “I wish I could go to play”
The first step would to create a vocabulary using all unique words from all documents (the vocabulary).¶
For this small corpus, it would be: [I, am, feeling, very, happy, today, not, well, wish, could, go, to, play]¶
Then, for each word the frequency of the word in the corresponding document is inserted¶
We could plot all words as vectors in a n-dimensional space (n is the size of our vocabulary). Every document (sentence) would be represented by the sum of its individual word vectors.¶

But if the vocabulary is huge, it may lead to very sparse vectors (mainly composed by zeros).¶
Word Embeddings is an efficient and effective way of representing words as vectors. The whole body of the text is encapsulated in some space of much lower dimension. Instead of being individual vectors, all words are represented by a linear combination of a smaller set of vectors (usually around 200-300) and it is possible to explicitly define their relationship with each other. This is done using a neural network architecture like these:¶
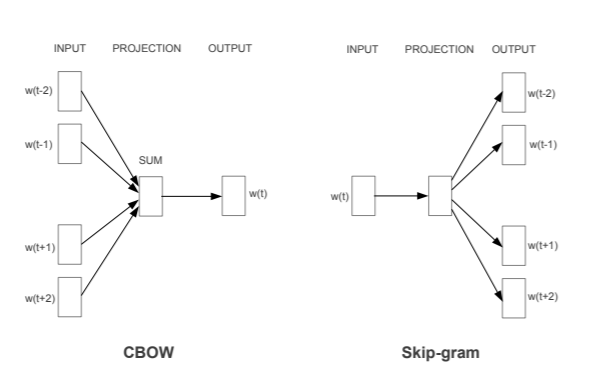
The vector space is abstract, but we could think of an analogy like this:¶
The resulting vector space can be illustrated by the following figure, that depicts how this space is able to capture relationships:¶
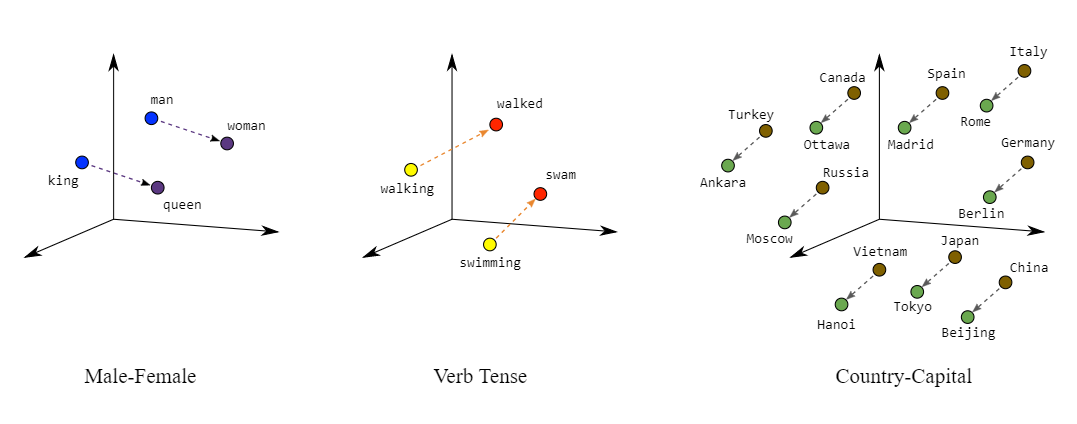
If we have corpora that spans different historical periods, we can analyse the evolution of the meaning of words:¶

Now let’s see it in practice!¶
Let’s download the German model:¶
[ ]:
! wget http://cloud.devmount.de/d2bc5672c523b086/german.model -P ./data/
Run the next cell: you should see a file aproximately this size: 738037646
[2]:
! ls -l ./data/german.model
-rw-rw-r-- 1 rsouza rsouza 738037646 jun 18 2018 ./data/german.model
Using German Word2vec trained on the German Wikipedia and German news articles - 15.5.2015¶
[2]:
# get trained model, files without a suffix, .bin or .model are treated as binary files
trained_model = gensim.models.KeyedVectors.load_word2vec_format('./data/german.model', binary=True)
[3]:
# remove original vectors to free up memory
trained_model.init_sims(replace=True)
Checking the words that are present in the model:¶
Change the word, as you like¶
[4]:
word = "Fruehstueck"
[k for k,w in trained_model.vocab.items() if k.startswith(word)][0:20]
[4]:
['Fruehstueck',
'Fruehstueckstisch',
'Fruehstuecksfernsehen',
'Fruehstuecksbuffet',
'Fruehstuecken',
'Fruehstuecks',
'Fruehstueck_Mittagessen',
'Fruehstuecksei',
'Fruehstueckspause',
'Fruehstuecksbuefett',
'Fruehstuecksraum',
'Fruehstueckstreffen',
'Fruehstueck_Tiffany',
'Fruehstuecksflocken',
'Fruehstueck_Abendessen',
'Fruehstuecks-',
'Fruehstuecksbroetchen',
'Fruehstuecksbueffet',
'Fruehstueck_Gruenen']
Examining the vector representation of a word¶
[5]:
word = "Wien"
print(trained_model[word].shape)
trained_model[word]
(300,)
[5]:
array([ 0.0238339 , 0.04943422, 0.0424271 , 0.0229144 , -0.00698469,
-0.00395486, 0.0729572 , 0.03326682, -0.05274953, -0.05048699,
-0.01097974, 0.01941785, -0.00286674, 0.05530975, -0.01717546,
0.00087026, -0.03554425, 0.08173548, 0.16878459, 0.05061062,
-0.0181843 , -0.04035862, 0.06884448, -0.03644295, -0.01597526,
-0.01427664, -0.03724374, -0.07765247, -0.04940229, 0.08755711,
0.0406867 , 0.10670323, 0.00047026, -0.08471008, 0.08366133,
-0.02376188, 0.00558794, 0.01392431, 0.00027164, 0.02758369,
-0.06885621, -0.09902706, 0.03808893, 0.04066271, -0.03511016,
0.00529123, 0.00842345, 0.08330758, 0.07514405, 0.0469595 ,
0.03891004, 0.02661347, -0.06389445, -0.13004696, -0.01151704,
0.04386351, -0.10433266, -0.04676365, -0.09454329, -0.01589428,
0.06392791, -0.13852148, 0.10145868, 0.04462037, 0.02761784,
0.03245379, 0.03132826, -0.00032424, -0.04573069, 0.00376301,
-0.03783711, 0.05745342, -0.00545467, 0.10306486, 0.08046119,
-0.01117319, 0.07071265, -0.01459174, -0.03979302, -0.05731346,
-0.0934009 , 0.00143596, 0.04024531, -0.06594911, 0.01442153,
-0.02157819, 0.00861198, -0.03360666, -0.00217473, -0.05325684,
-0.06063867, 0.05235587, -0.07148876, 0.14030436, 0.08084998,
0.05225494, 0.02232727, -0.0375154 , -0.05153104, 0.04204175,
0.06927375, -0.0213337 , -0.0359464 , -0.0986684 , -0.10689045,
0.0422255 , -0.04803819, -0.03605939, 0.0329151 , 0.07575817,
0.05432944, -0.01006523, -0.0031073 , -0.01198116, -0.00700702,
-0.04663587, -0.06598163, -0.02608355, 0.03399949, 0.08767203,
-0.07043833, 0.05742546, 0.02844732, -0.0641215 , 0.03557531,
-0.00807026, -0.01884014, -0.00610054, 0.10268665, -0.08756135,
0.03461902, 0.01096097, 0.01700337, 0.02436678, -0.07595782,
0.09562863, 0.02614196, -0.01443401, -0.01836962, 0.04879408,
-0.03684777, -0.0711819 , -0.03422985, -0.07293234, -0.06803517,
-0.01470779, 0.02610919, 0.03275155, 0.0098528 , 0.04751247,
-0.02650394, -0.04922485, 0.0966305 , 0.06181309, -0.07539852,
0.03954438, 0.06627589, 0.0742739 , 0.01676205, 0.09427383,
0.10264442, 0.010852 , 0.01417513, -0.01856818, -0.02165503,
-0.0018881 , -0.01918374, 0.03137087, -0.0257187 , 0.04286152,
-0.0495176 , 0.01291669, -0.02210455, 0.04033438, -0.07039625,
-0.01298227, -0.03088601, -0.0148988 , 0.0213136 , -0.00308892,
-0.03916396, 0.00842758, -0.07342014, 0.05616776, -0.0369697 ,
-0.01181048, 0.06073389, -0.01649796, -0.0186084 , -0.00040346,
-0.0586713 , -0.0343927 , 0.01033644, 0.11091413, -0.0552993 ,
0.01196672, -0.08076494, -0.00777858, 0.04654175, 0.04052089,
0.03798108, -0.02726053, -0.10897127, 0.09802596, -0.02641043,
0.04788393, -0.0549567 , -0.01355664, -0.10841926, 0.06741678,
-0.04732709, 0.0523398 , 0.0454935 , 0.01515049, -0.02464675,
-0.08356615, 0.04951958, 0.01018465, 0.04417115, 0.07852858,
0.0225594 , -0.00074988, -0.04641408, 0.05589736, -0.1395837 ,
0.08130305, 0.17868005, 0.01470505, -0.04527267, -0.01598396,
0.01736509, 0.03316962, -0.09426542, -0.03690347, 0.11291514,
0.02533004, 0.00281629, -0.05241821, -0.16159989, 0.06563755,
0.01156138, 0.09131934, -0.05008974, -0.0002698 , -0.00804178,
0.05430156, -0.0405793 , -0.15452953, 0.09096871, 0.00484005,
0.08594571, 0.00039966, -0.05168523, -0.04028896, -0.01445882,
0.03440348, -0.02790812, -0.0124769 , -0.08990064, -0.09347708,
0.09387834, -0.03679283, 0.09682948, 0.03489142, -0.02784478,
-0.13160774, 0.14424536, 0.00976484, -0.07370998, -0.0155739 ,
-0.10138693, 0.00144212, 0.06416222, -0.04055014, -0.09581374,
-0.0326473 , -0.00590264, 0.00297864, 0.0474886 , 0.01101959,
0.00588132, 0.05759835, 0.02765032, -0.03065836, -0.00759589,
0.06519953, -0.03736394, -0.14547537, 0.00297634, -0.02188038,
0.04868366, 0.02270741, 0.04986598, -0.03618561, 0.00272301,
-0.01465227, 0.06472276, -0.03055525, -0.022267 , 0.00160853],
dtype=float32)
There are different metrics for vector distances¶
[6]:
print(trained_model.similarity('kopf', 'blau'))
print(trained_model.distance('kopf', 'blau'))
0.4494617
0.5505383014678955
What are the words most similar to each word of the list?¶
Change the words, as you like¶
[20]:
words = ['Werkzeug', 'blau', 'rot', 'kopf', 'Gewerbe']
series = []
for word in words:
series.append(pd.DataFrame(trained_model.most_similar(word, topn=10),
columns=[f"Similar_{word}", "similarity"]))
df = pd.concat(series, axis=1)
df.head(10)
[20]:
| Similar_Werkzeug | similarity | Similar_blau | similarity | Similar_rot | similarity | Similar_kopf | similarity | Similar_Gewerbe | similarity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Werkzeuge | 0.783259 | rot | 0.828190 | gelb | 0.835019 | sperrangelweit_offen | 0.623633 | Gastronomie | 0.690014 |
| 1 | Schraubenzieher | 0.734391 | gruen | 0.795948 | gruen | 0.829063 | angewurzelt | 0.593449 | Handel_Handwerk | 0.689797 |
| 2 | Schweissgeraet | 0.733918 | gelb | 0.783880 | blau | 0.828190 | bombenfest | 0.588438 | Gewerbebetriebe | 0.681497 |
| 3 | Werkzeugen | 0.722541 | orange | 0.774674 | schwarz | 0.782608 | hinterm_Tresen | 0.586510 | Gewerbetreibende | 0.673723 |
| 4 | Akkuschrauber | 0.719295 | grau | 0.762676 | orange | 0.771306 | roten_Lettern | 0.586199 | Gewerbe_Industrie | 0.673452 |
| 5 | Werkzeugkoffer | 0.712236 | Blau | 0.759318 | grau | 0.731490 | Haende_Hosentaschen | 0.584047 | Kleingewerbe | 0.669487 |
| 6 | Stemmeisen | 0.711309 | schwarz | 0.755070 | rot_gelb | 0.723444 | Praesentierteller | 0.579342 | Handel_Gewerbe | 0.668937 |
| 7 | Bolzenschneider | 0.701930 | braun | 0.744812 | rote | 0.722512 | gluckst | 0.577661 | Einzelhandel | 0.667275 |
| 8 | Brecheisen | 0.697887 | tuerkis | 0.736878 | braun | 0.721413 | splitterfasernackt | 0.576129 | Dienstleistung | 0.664609 |
| 9 | Bohrmaschine | 0.697744 | rosa | 0.733246 | lila | 0.719744 | wackeligen_Beinen | 0.574928 | Dienstleistungsbetriebe | 0.649108 |
What is the word that does not fit?¶
Change the words, as you like¶
[8]:
word1, word2, word3, word4, word5 = 'blau','rot','feld','gruen','gelb'
#word1, word2, word3, word4, word5 = 'Fruehstueck', "Fenster", 'Abendessen','Mittagessen', "Soupe"
#word1, word2, word3, word4, word5 = "Vater", "Mutter", "Sohn", "Tochter", "Oma"
#word1, word2, word3, word4, word5 = "Frankreich","England","Deutschland","Berlin","Oesterreich"
print(trained_model.doesnt_match([word1, word2, word3, word4, word5]))
feld
/usr/local/lib/python3.8/dist-packages/gensim/models/keyedvectors.py:877: FutureWarning: arrays to stack must be passed as a "sequence" type such as list or tuple. Support for non-sequence iterables such as generators is deprecated as of NumPy 1.16 and will raise an error in the future.
vectors = vstack(self.word_vec(word, use_norm=True) for word in used_words).astype(REAL)
Let’s make some vectorial operations with words?¶
Change the words, as you like!¶
[9]:
positive_vectors = ['Koenig', 'frau']
negative_vectors = ['mann']
#positive_vectors = ['frau', 'blau']
#negative_vectors = ['mann']
for result in trained_model.most_similar(positive=positive_vectors,
negative=negative_vectors):
print(result)
('Prinzen', 0.6192535161972046)
('Prinzessin', 0.6132442951202393)
('Koenigin', 0.5914254188537598)
('Prinz', 0.5866174697875977)
('Koenigin_Niederlande', 0.5534396767616272)
('Regentin', 0.542670488357544)
('Maerchenprinzen', 0.5391709804534912)
('Majestaet', 0.5391337871551514)
('Thron', 0.5360094308853149)
('Thronfolger', 0.5285029411315918)
Let’s try reducing the dimensionality of the space and see a 2D projection of the vectors…¶
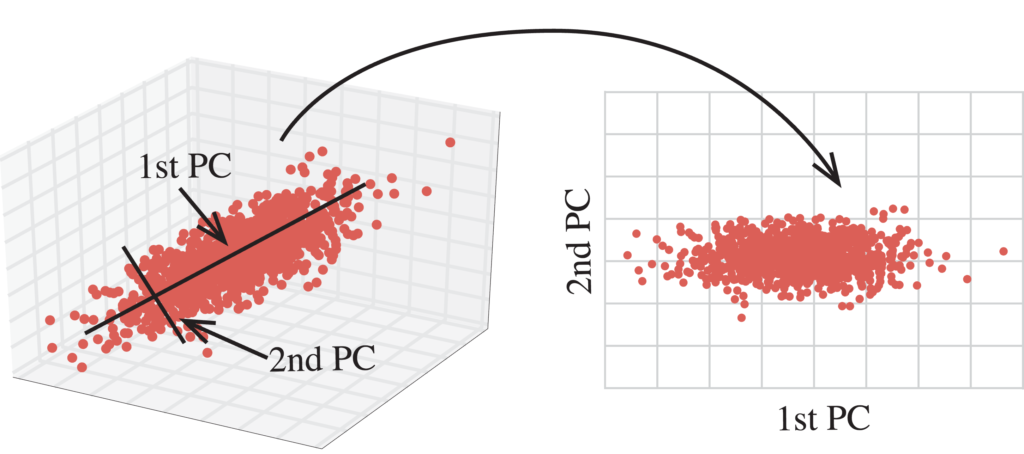
These helper functions will reduce the dimensionality and print the 2D projections
[11]:
def draw_words(model, words, pca=False, alternate=True, arrows=True, x1=3, x2=3, y1=3, y2=3, title=''):
# get vectors for given words from model
vectors = [model[word] for word in words]
if pca:
pca = PCA(n_components=2, whiten=True)
vectors2d = pca.fit(vectors).transform(vectors)
else:
tsne = TSNE(n_components=2, random_state=0)
vectors2d = tsne.fit_transform(vectors)
# draw image
plt.figure(figsize=(15,15))
if pca:
plt.axis([x1, x2, y1, y2])
first = True # color alternation to divide given groups
for point, word in zip(vectors2d , words):
# plot points
plt.scatter(point[0], point[1], c='r' if first else 'g')
# plot word annotations
plt.annotate(
word,
xy = (point[0], point[1]),
xytext = (-7, -6) if first else (7, -6),
textcoords = 'offset points',
ha = 'right' if first else 'left',
va = 'bottom',
size = "x-large"
)
first = not first if alternate else first
# draw arrows
if arrows:
for i in range(0, len(words)-1, 2):
a = vectors2d[i][0] + 0.04
b = vectors2d[i][1]
c = vectors2d[i+1][0] - 0.04
d = vectors2d[i+1][1]
plt.arrow(a, b, c-a, d-b,
shape='full',
lw=0.1,
edgecolor='#bbbbbb',
facecolor='#bbbbbb',
length_includes_head=True,
head_width=0.08,
width=0.01
)
# draw diagram title
if title:
plt.title(title)
[12]:
wordpairs = ["Mann", "Vater",
"Frau", "Mutter",
"Mutter", "Oma",
"Vater", "Grossvater",
"Junge", "Mann",
"Maedchen", "Frau",
]
draw_words(trained_model, wordpairs, True, True, True, -2.5, 2.5, -2.5, 2.5, r'$PCA Visualisierung:')
_32_0.png)
[13]:
# plot currencies
wordpairs = ["Schweiz", "Franken",
"Deutschland", "Euro",
"Grossbritannien", "britische_Pfund",
"Japan", "Yen",
"Russland", "Rubel",
"USA", "US-Dollar",
"Kroatien", "Kuna",
"Oesterreich", "Euro",]
draw_words(trained_model, wordpairs, True, True, True, -2, 2, -2, 2, r'$PCA Visualisierung:')
_33_0.png)
Now it is time to build your own projection…¶
Change the words, as you like!¶
[14]:
# change any pairs of words and run the cell again
wordpairs = ["klein", "kleiner",
"klein","kleinste",
"gross", "grosser",
"gross", "groessten"
]
draw_words(trained_model, wordpairs, True, True, True, -2.5, 2.5, -2.5, 2.5, r'$PCA Visualisierung:')
_35_0.png)
Now we are going to build a graph with similar words…¶
[15]:
def build_neighbors(word, model, nviz=10):
g = nx.Graph()
g.add_node(word, color='r')
viz1 = model.most_similar(word, topn=nviz)
for v in viz1:
g.add_node(v[0], color='b')
g.add_weighted_edges_from([(word, v, w) for v,w in viz1 if w> 0.65])
for v in viz1:
for l in model.most_similar(v[0], topn=nviz):
g.add_node(l[0], color='y')
g.add_weighted_edges_from([(v[0], v2, w2) for v2,w2 in model.most_similar(v[0])])
for v in viz1:
g.add_node(v[0], color='b')
g.add_node(word, color='r')
return g
Change the word, as you like!¶
[16]:
word = 'Oesterreich'
#word = 'Akademie'
#word = "Kant"
#word = "Rock"
G = build_neighbors(word, trained_model, 10) # number of similar words to display
pos = nx.spring_layout(G, iterations=100)
nx.draw_networkx(G,
pos=pos,
node_color=nx.get_node_attributes(G,'color').values(),
node_size=1000,
alpha=0.8,
font_size=12,
)
_39_0.png)
Some exercises:¶
- Let’s supose you want to find out if the German Wikipedia has any gender biases using vectorial analogies. Could you think of a test?hint: see this paper
- Can you train your own word2vec model from your own corpora?hint: see the documentation
Let’s use one of the corpus available in this course:
[10]:
path = './summerschool2020/datasets/MPR/TEI/'
teixmlfiles = [f for f in os.listdir(path) if f.endswith('xml')]
[11]:
class WordTrainer(object):
def __init__(self, dir_name):
self.dir_name = dir_name
def __iter__(self):
for idx,file_name in enumerate([f for f in os.listdir(self.dir_name) if f.endswith('xml')]):
soup = bs(open(os.path.join(self.dir_name, file_name),'r'), 'lxml').text
words = [word.lower() for word in soup.split()]
yield words
Next cell will train the model. It may take a while…
[12]:
generator = WordTrainer(path)
# Train word2vec model with 200 dimensions, 10 words window and 5 iterations
word_vector_model = gensim.models.Word2Vec(generator, size=200, window=10, min_count=5)
[16]:
# word_vector_model.wv.vocab.keys()
word = 'minist'
[k for k in word_vector_model.wv.vocab.keys() if k.startswith(word)][0:20]
[16]:
['ministerrates',
'ministerium',
'ministerratsprotokolle',
'ministerratsprotokolle,',
'ministerrat.dtd',
'ministerkonferenz,',
'ministerkonferenz',
'ministerpräsidenten,',
'ministers',
'ministerien',
'ministerrat,',
'ministerrat',
'minister',
'ministerrate',
'ministerium.',
'ministern',
'ministeriums',
'ministerberatungen',
'ministerkonferenz]',
'ministerkonferenzen']
[18]:
words = ['ministerrates', 'ministerium', 'ministerratsprotokolle', 'ministerratsprotokolle,']
series = []
for word in words:
series.append(pd.DataFrame(word_vector_model.wv.most_similar(word, topn=10),
columns=[f"Similar_{word}", "similarity"]))
df = pd.concat(series, axis=1)
df.head(10)
[18]:
| Similar_ministerrates | similarity | Similar_ministerium | similarity | Similar_ministerratsprotokolle | similarity | Similar_ministerratsprotokolle, | similarity | |
|---|---|---|---|---|---|---|---|---|
| 0 | ministerrats | 0.542947 | ministeriums | 0.698295 | österreichisch-ungarischen | 0.832775 | 1848-1866 | 0.940745 |
| 1 | ministerrates, | 0.534776 | ministerio | 0.619384 | (https://creativecommons.org/licenses/by/4.0/d... | 0.775498 | (teilbestand) | 0.920847 |
| 2 | protokolle | 0.495456 | armeeoberkommando, | 0.549736 | online | 0.774431 | https://www.archivinformationssystem.at/detail... | 0.875206 |
| 3 | abteilung | 0.489594 | justizministerium | 0.519481 | österreichs | 0.744246 | ömr-prot | 0.858871 |
| 4 | kriegsministeriums | 0.477623 | reichsministerium | 0.511560 | monarchie | 0.730170 | quelle | 0.807843 |
| 5 | 1848–1867, | 0.475620 | ministern | 0.508819 | herausgeber/in: | 0.717563 | kk | 0.739119 |
| 6 | ministerrats, | 0.474603 | ministers | 0.507961 | (mrp) | 0.706194 | tei-datei | 0.704549 |
| 7 | reichstages | 0.470342 | kriegsministerium | 0.506486 | heindl. | 0.686432 | ka | 0.698466 |
| 8 | staatsministeriums | 0.470340 | handelsministerium | 0.505275 | wissenschaftlicher | 0.677123 | at-oesta/hhsta | 0.632534 |
| 9 | handelsministers | 0.465075 | minister | 0.487464 | malfèr. | 0.676343 | notesstmt | 0.557569 |
[ ]: